Scraping Web sources: Two illustrations
Per request from a couple of students in a course on open data that I contribute to, here's a short guide to the "why" and "how" questions about (Web) scraping, with links to examples to illustrate the usefulness of the technique.
What is scraping?
(Web) Scraping consists in writing computer code to automate the download and/or parsing of online data sources. In practice, this means writing little scripts in your favourite programming language to transform Web pages into datasets or databases.
Two other verbs related to Web scraping are Web crawling, i.e. collecting Web pages without looking at how they are structured internally, and Web parsing, i.e. reading the information found in the Web pages.
Basically, Web scraping amounts to “Web crawling + Web parsing.”
What's the point?
Scraping is a way to create original datasets from highly diverse online sources, and because there is a cost of entry to online data collection, knowing how to scrape data will put you in a nice position on various employment markets, especially now that "data science" is gradually being acknowledged as a valuable skill in itself.
That is not to say that scraping is all that data science is about—but it certainly is one of its current building blocks, and rightly so, given the increasing availability of "raw" data on open data portals, and the wide availability of even more data online in formats, such as HTML pages, that are meant for presentation rather than for analysis.
The two examples below are examples of networks that were assembled by scraping two online sources: theses.fr, the French portal of PhD dissertations, and parliament.uk, the official website of the UK Parliament.
A simple example
The network below shows connections between the scientific disciplines of a large sample of French PhD dissertations. Some descriptive information about the network appear in this blog post (in French).

In order to build this network, I downloaded several thousands of XML files containing standardised information about each dissertation that was supervised either by a social scientist, or by a political scientist.
The download loop and network construction procedure are available online as a bunch of short R scripts:
The first script shows how to pass a search query to the portal of French PhD dissertations, theses.fr.
What I call a "search query" is what you send to a website that comes with a search form. For instance, when you send a search query to Google, the URL of the page that opens as a result includes
?q=[your-query]The search query might be sent to the website through different means, but the concept will stay the same: load a Web page with the right information, and get its results.
The second script shows how to download the XML files that the website uses to show information on the dissertations.
And the third script shows how to parse (i.e. read) the files, in order to extract the (metadata) variables of interest.
In this example, the scraping job was an easy one because the website comes with a documented API. This means that all I had to do to get to the data was to emulate a search request on the website, parse its results, and then download the data in a well-defined format, which was then very simple to parse.
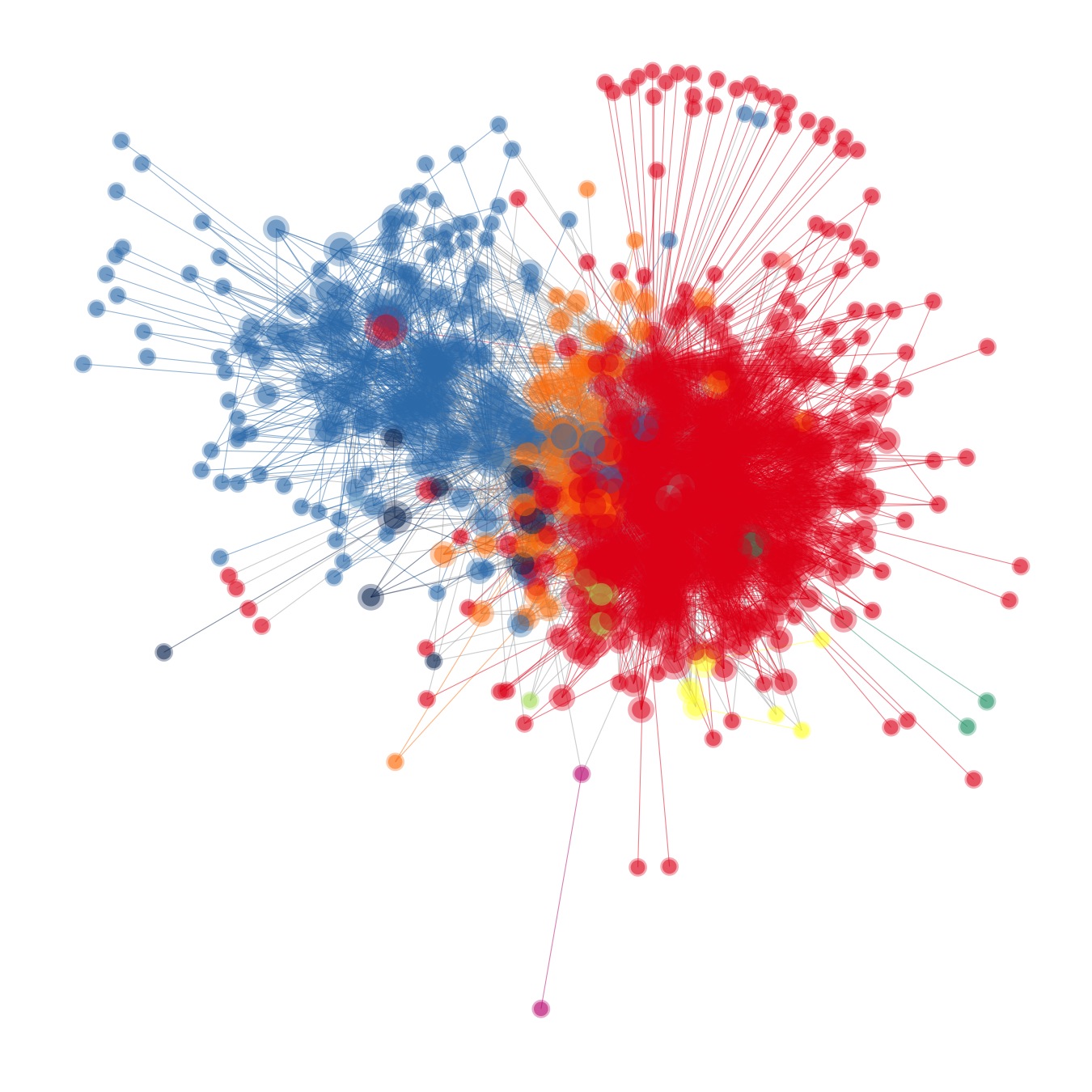
A more complex example
Things can get a bit more complicated when the targeted website does not come with an API, which usually means that the data have to be collected as HTML Web pages, and then processed to a digestible data format.
Thankfully, HTML is a derivative of XML, which means that, when the HTML code of the source is well-structured (which is not always the case), it can be parsed just as easily as in the previous example.
Here's one of the graphical results of a project based on parsing tons of HTML files:
The scraping code for this project is also very simple: the data it relies upon are available as online HTML tables, which can be parsed using either XPath syntax or, as I do in my code, CSSSelect syntax. An example of the latter syntax is:
#number-list tbody td:first-child
The example means:
Give me the first
<td>element, which is a table cell, of the<tbody>element, which holds the contents of a table, of the table identified asnumber-list.
Using such expressions, one can extract all relevant information from the table, and then reshape it into a dataset that fits the needs of the analysis. The data workflow for this project therefore looks like:
Get the table for year 2015-16
Read its contents
Get the table for year 2014-15
Read its contents
Get the table for year 2013-14
etc.
where “Read its contents” amounts to reading the information of each table cell that is relevant to the analysis.
Note how the workflow above does not rely on a search query: instead, we use the structure of the website to access the target data by year broken down by year (or more exactly, by parliamentary session).
This example is only slightly more complex than the previous one. A much more complex project would involve sending complex (instead of straightforward) search queries, and/or retrieving loosely (instead of perfectly) structured results.
This note is a first draft, which I might expand if I get enough student feedback.
- First published on December 14th, 2016