Scraping form results with httr
This note shows how to use the httr package to scrape the results of a search form.
Example
In this blog post, Baptiste Coulmont looks at some French nomination decrees published in the Journal officiel de la République française (JORF). Every nomination published by the French civil service is expected to be available from this JORF search form.
Looking at the HTML source of the search form, it appears that the form submits its information to a separate Web page:
<form action="/rechExpMesuresNominatives.do" method="post" ...
Looking further in the source, the form parameters that can be manipulated by the user are the following:
champNom,champPrenom,champFonction,champMinistereandchampDecorationallow the user to search for particular persons or for particular kinds of nominationscheckboxPeriodeis a checkbox that can be set to"on"to search in a date interval; the two dates are configurable through six day, month and year parameters that start withchampDatePublication.
By setting up a POST request with httr, we can programmatically scrape any temporal interval from the search form. Doing so, we can scrape the first page of the results, determine how many pages of results there are, and then scrape all nomination decrees available through the search form.
Method
Now that we know the scraping target, let's
- download all JORF search results for available years, and
- download a sample of JORF decisions in that time interval
We will skip the first four years of data, which our early tests flagged as almost entirely empty, and start in 1994, up to 2015, while downloading all matching nominative measures along the way. We are going to use
dplyrto build a data frame containing the nominative measures that we have scrapedhttrto formulate thePOSTrequest that we want to send to the JORF search formrvestto read information inside the HTML pages that we will downloadstringrto perform string concatenation and text cleaning on the data
Talking to the search form through httr is done by
- targetting the search page
rechExpMesuresNominatives.do - while setting the values of
champNom,champPrenom, etc.
Data
Here's a 150-lines scraper set that downloads all results for the years previously mentioned as well as all decisions to nominate someone to either "ambassador" or "consul" status, two small nomination categories that return less than a hundred documents per year:
The download method consists in downloading the complete list of nominations published during the sampled time periods, which is slow but allows to compare the quantities of sampled documents to the quantities of the full data. It also allows to change the document sample entirely if needed.
The script will show that early years (1990–1993) return less total documents than all following years, or even no documents at all for year 1993: some of the data for that period are highly likely to be missing.
Results
The plot below shows the number of nominations per time period, with post-electoral periods shown in darker tone; the plot also shows the breakdown by gender, which is extremely biased towards males:
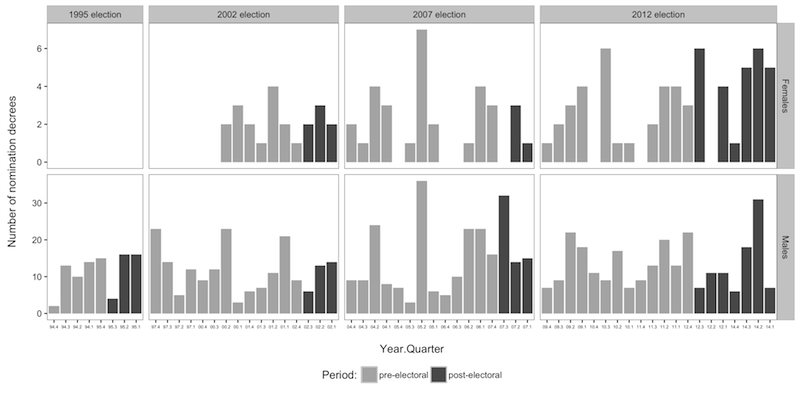
Post-electoral periods do not seem to differ radically from pre-electoral periods as far as the examined nominations go. There are, however, several periods during which nominations to either ambassador or consul status have been markedly more numerous.
The code to run the scraper and produce the plot above appears in this Gist.
- First published on January 10th, 2016